JS函数式编程 - 函子和范畴轮
在前面几篇介绍了函数式比较重要的一些概念和如何用函数组合去解决相对复杂的逻辑。是时候开始介绍如何控制副作用了。
数据类型
我们来看看上一篇最后例子:
1 | const split = curry((tag, xs) => xs.split(tag)) |
这里其实reverseWords还是很难阅读,你不知道他入参是啥,返回值又是啥。你如果不去看一下代码,一开始在使用他的时候,你应该是比较害怕的。 “我是不是少传了一个参数?是不是传错了参数?返回值真的一直都是一个字符串吗?”。这也是类型系统的重要性了,在不断了解函数式后,你会发现,函数式编程和类型是密切相关的。如果在这里reverseWords的类型明确给出,就相当于文档了。
但是,JavaScript是动态类型语言,我们不会去明确的指定类型。不过我们可以通过注释的方式加上类型:
1 | // reverseWords: string => string |
上面就相当于指定了reverseWords是一个接收字符串,并返回字符串的函数。
JS 本身不支持静态类型检测,但是社区有很多JS的超集是支持类型检测的,比如Flow还有TypeScript。当然类型检测不光是上面所说的自文档的好处,它还能在预编译阶段提前发现错误,能约束行为等。
当然我的后续文章还是以JS为语言,但是会在注释里面加上类型。
范畴论相关概念
范畴论其实并不是特别难,不过是些抽象点的概念。而且我们其实不需要了解的特别深,函数式编程很多概念是从范畴论映射过来的。了解范畴论相关概念有助于我们理解函数式编程。另外,相信我,只要你小学初中学过一元函数和集合,看懂下面的没有问题。
定义
范畴的定义:
- 一组对象,是需要操作的数据的一个集合
- 一组态射,是数据对象上的映射关系,比如 f: A -> B
- 态射组合,就是态射能够几个组合在一起形成一个新的态射


一个简单的例子,上图来自维基百科。上面就是一个范畴,一共有3个数据对象A,B,C,然后f和g是态射,而gof是一组态射组合。是不是很简单?
其中态射可以理解是函数,而态射的组合,我们可以理解为函数的组合。而里面的一组对象,不就是一个具有一些相同属性的数据集嘛。
函子(functor)
函子是用来将两个范畴关联起来的。
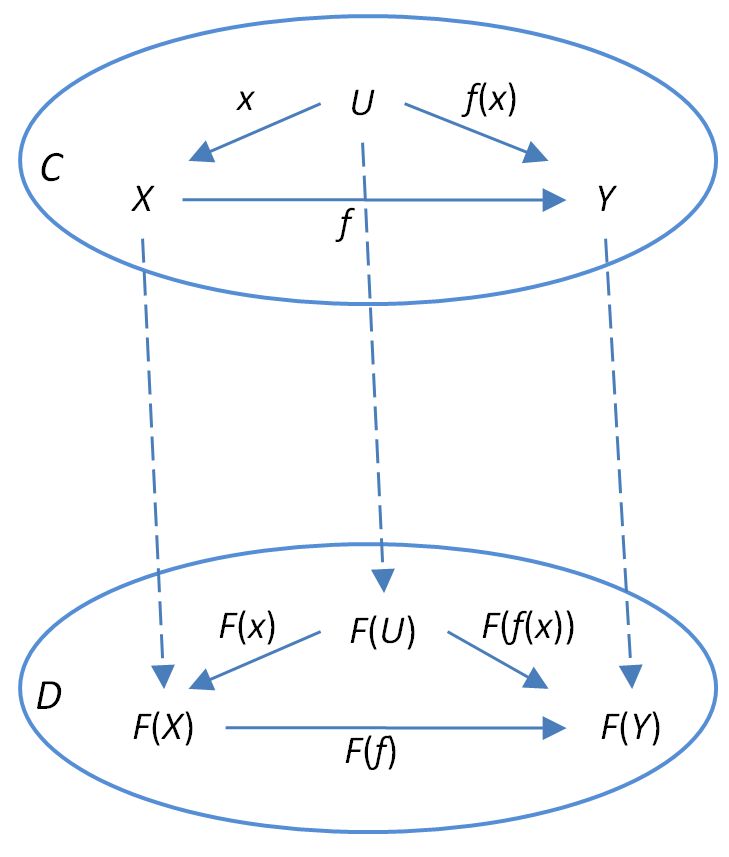
图片出处:https://ncatlab.org/nlab/show/functor
对应上图,比如对于范畴 C 和 D ,函子 F : C => D 能够:将 C 中任意对象X 转换为 D 中的 F(X); 将 C 中的态射 f : X => Y 转换为 D 中的 F(f) : F(X) => F(Y)。你可以发现函子可以:
- 转换对象
- 转换态射
构建一个函子(functor)
Container
正如上面所说,函子能够关联两个范畴。而范畴里面必然是有一组数据对象的。这里引入Container,就是为了引入数据对象:
1 | class Container { |
我们声明了一个Container的类,然后给了一个静态的of方法用于去生成这个Container的实例。这个of其实还有个好听的名字,卖个关子,后面介绍。
我们来看一下使用这个Container的例子:
1 | // Container(123) |
正如上面看到的,Container是可以嵌套的。我们仔细看一下这个Contaienr:
- $value的类型不确定,但是一旦赋值之后,类型就确定了
- 一个Conatiner只会有一个value
- 我们虽然能直接拿到$value,但是不要这样做,不然我们要个container干啥呢
第一个functor
让我们回看一下定义,函子是用来将两个范畴关联起来的。所以我们还需要一个态射(函数)去把两个范畴关联起来:
1 | class Container { |
先来用一把:
1 | const concat = curry((str, xs) => xs.concat(str)) |
不晓得上面的curry是啥的看第二篇文章。
你可能会说:“哦,这是你说的functor,那又有啥用呢?”。接下来,就讲一个应用。
不过再讲应用前先讲一下这个of,其实上面这种functor,叫做pointed functor, ES5里面的Array就应用了这种模式:Array.of。他是一种模式,不仅仅是用来省略构建对象的new关键字的。我感觉和scala里面的compaion object有点类似。
Maybe type
在现实的代码中,存在很多数据是可选的,返回的数据可能是存在的也可能不存在:
1 | type Person = { |
上面是flow里面的类型声明,其中?代表这个数据可能存在,可能不存在。我相信像上面的数据结构,你在接收后端返回的数据的时候经常遇到。假如我们要取这个age属性,我们通常是怎么处理的呢?
当然是加判断啦:
1 | const person = { info: {} } |
你会发现为了取个age,我们需要加很多的判断。当数据中有很多是可选的数据,你会发现你的代码充满了这种类型判断。心累不?
Okey,Maybe type就是为了解决这个问题的,先让我们实现一个:
1 |
|
应用一波:
1 |
|
来复盘一波,上面的map依然是一个functor(函子)。不过呢,在做类型转换的时候加上了逻辑:
1 | map(fn) { |
所以也就是上面的转换关系可以表示为:

其实一看图就出来了,“哦,你把判断移动到了map里面。有啥用?”。ok,罗列一下好处:
- 更安全
- 将判断逻辑进行封装,代码更简洁
- 声明式代码,没有各种各样的判断
其实,不确定性,也是一种副作用。对于可选的数据,我们在运行时是很难确定他的真实的数据类型的,我们用Maybe封装一下其实本身就是封装这种不确定性。这样就能保证我们的一个入参只有可能会返回一种输出了。